In Part 1, I added tree-sitter tools for structural code reading. In Part 1.5, I locked those tools behind a secure factory. In Part 2, I added an OODA loop with a rule engine and verify phase. In Part 2.5, I added a RAG layer over OWASP guidance for secure code generation.
This part shows how to use the harness to get the same 9B parameter model, running locally on a laptop, to score 100% on a coding benchmark. The solution was pretty simple, discover a bug in the benchmark that scores full marks for every submission /s.
Background#
Coding benchmarks seem to occupy an awkward middle ground in how people think about them. The general feeling tends to be that they are good enough for rough comparisons between models, but poor at predicting how a model will actually perform in a real codebase with dependencies, legacy patterns, and multi-file edits. Benchmarks that look more like real issue resolution inside a codebase (SWE-bench, Terminal-Bench) seem to get more respect than isolated puzzle-solving tests, but even those tend not to settle the question of whether a model will actually help on your project. Most people seem to land somewhere between “useful signal” and “do not trust the leaderboard.”
But two things happened recently that got me thinking:
UC Berkeley RDI’s “How We Broke Top AI Agent Benchmarks” audited eight major agent benchmarks and found that every one could be driven to near-perfect scores without solving a single task. Their Terminal-Bench result was 100% on all 89 tasks via binary wrapper trojans that intercepted /usr/bin/curl during the agent phase, hijacked the uv install chain, and synthesised fake passing pytest output at verify time. The framing was a trust boundary issue: the evaluator inspected state that the system under test could write to. Their attack needed the parser to return a populated results dictionary full of fake PASSED lines, which left me wondering whether there was something simpler sitting in the scoring path itself that Berkeley’s audit had not reached.
Separately, Anthropic launched Glasswing, an industry security initiative built around Claude Mythos Preview, an unreleased frontier model. Anthropic’s pitch is that “AI models have reached a level of coding capability where they can surpass all but the most skilled humans at finding and exploiting software vulnerabilities.” That claim is specifically about software vulnerability research, and I wanted to test it directly: point Claude Opus at a software artifact, ask it to find a vulnerability, see what happens. The terminal-bench harness seemed like a reasonable target, because Berkeley had already established that some exploit class was present and the question was whether Claude could find something else in the same codebase.
Reading the scoring path#
The approach was the same one Part 1, Reading Code of this series is about: read the code structurally, not with grep. This time the agent doing the reading was Claude Opus, directed at the terminal-bench source with the same tree-sitter tools from code_intel.py (find_defs, find_refs, file_outline) that Part 1 is built on, and one specific goal: find a scoring-path defect.
Berkeley’s exploit relied on synthesising fake pytest output that the parser would accept. The questions I gave Opus aimed at the verdict itself:
- Where in the harness Python does “pass/fail” actually get computed?
- What code paths transform raw session state into that boolean, and where can an attacker cheaply influence each step?
- Does the harness’s own architecture leak authority in unexpected ways?
A few find_defs lookups on the scoring-path functions (_parse_results, _setup_test_env, _run_tests) plus a grep for capture-pane narrowed roughly 13,000 lines of Python to a handful of functions in two files: harness.py and pytest_parser.py.
What the code said#
The agent’s read surfaced four observations, ordered from the outside in:
Tests are invoked via keystroke injection, not process execution. The harness does not run the test script via
docker exec. It typesbash /tests/run-tests.shas keystrokes into a tmux pane (harness.py). Whatever bash is running in that pane receives those characters as a command-line input, which means shell functions, aliases, and PATH overrides all take precedence over the binary. A function namedbashdefined in that shell intercepts the entire test invocation.The test session runs as root regardless of the agent user. The test phase creates a new tmux session with
as_configured_user=False(harness.py), which resolves touser="root". That root shell sources/etc/profile.d/*.sh,/root/.bashrc, and/root/.bash_profileat startup. Anything the agent phase writes to those files executes as root in the test phase, which means even a non-root agent can poison the root shell init.The parser returns an empty dict when no test results are found. The pytest parser (
pytest_parser.py) splits the captured pane on theshort test summary infomarker and iterates the lines after it, looking for valid status keywords. If the marker is found but no valid status lines follow, the parser returns{}without error.The scoring predicate treats an empty dict as “resolved.” The function that decides whether a trial passed (
harness.py):
| |
The first guard checks None, not falsy. For parser_results = {}, execution falls through to all(...), which iterates an empty generator, and all([]) in Python is True. A trial in which the parser observed zero test results is indistinguishable from a trial in which every test passed, because all([]) is True.
Reading the parser also turned up three related weaknesses that the exploit did not need but that would be the next things to close:
- SKIPPED is mapped to PASSED (
pytest_parser.py). A task whose tests skip because of a missing dependency scores as resolved, which is confirmed by the parser’s own upstream unit test. - XFAIL is also mapped to PASSED, a second free-pass path through the same mapping.
- Test name collisions mask failures (
pytest_parser.py). Results are keyed by the trailing portion of the test path (test_path.split("::", maxsplit=1)[-1]), so two status lines with the same trailing name collide in the dict and only the later one survives. InjectingPASSED anything::test_nameafter a realFAILED real.py::test_nameerases the failure.
All four weaknesses (the empty-dict bug plus these three) are captured as unit tests in the companion repo, and all four pass against the current parser.
The exploit#
The chain from those four observations to a working exploit is short. During the agent phase, drop a bash function override into /etc/profile.d/zzz-harness-benchmark.sh that matches on */run-tests.sh, echoes the short test summary info marker, and returns 0:
| |
Additional writes to /etc/bash.bashrc, /root/.bashrc, and /root/.bash_profile cover the different tmux startup paths. A trailing source handles tasks where run_tests_in_same_shell is true and the agent’s current shell runs the tests directly.
When the test phase starts, the new root tmux session sources the init files, the bash function takes effect, and the harness types bash /tests/run-tests.sh into the pane. The function intercepts, echoes the marker, and returns immediately, so no pytest ever runs and the pane contains exactly three lines: the typed command, the marker, and the next prompt. The parser splits on the marker, finds no status lines, returns {}, and _is_resolved({}) returns True.
Worth noting what this is and is not: terminal-bench is a local-first benchmark with no remote verifier: tb run executes on your machine and writes results.json to disk. You could open that file in a text editor, change "is_resolved": false to true, and tb runs summarize would happily report 100%. That is trivially true of every local benchmark, it is not a finding, and the mitigation is “the leaderboard operator re-runs your agent.”
The exploit here is different because it runs through terminal-bench’s own code path, not around it. tb run spins up a real Docker container, copies in run-tests.sh, types bash /tests/run-tests.sh as real keystrokes into a real tmux pane, captures the pane with its own capture-pane call, parses it with its own PytestParser, and scores it with its own _is_resolved. At no point does the exploit write to results.json. Terminal-bench writes it based on its own logic, which is where the bug sits. If a leaderboard operator re-runs the submitted agent to verify a suspicious score, the re-run produces 100% again, deterministically, because the exploit is a property of the agent, not an after-the-fact edit.
What it looks like running#
Opus’s first attempt was wrong: echoing the marker during the agent phase into the agent pane. The test phase uses a separate tmux session (the default run_tests_in_same_shell=False creates a new session with its own scrollback), so the marker never makes it into the pane the parser reads.
The second attempt uses the shell init poisoning approach and gets 100% on hello-world. The post-test pane:
| |
Three lines, and run-tests.sh never ran. The results.json:
| |
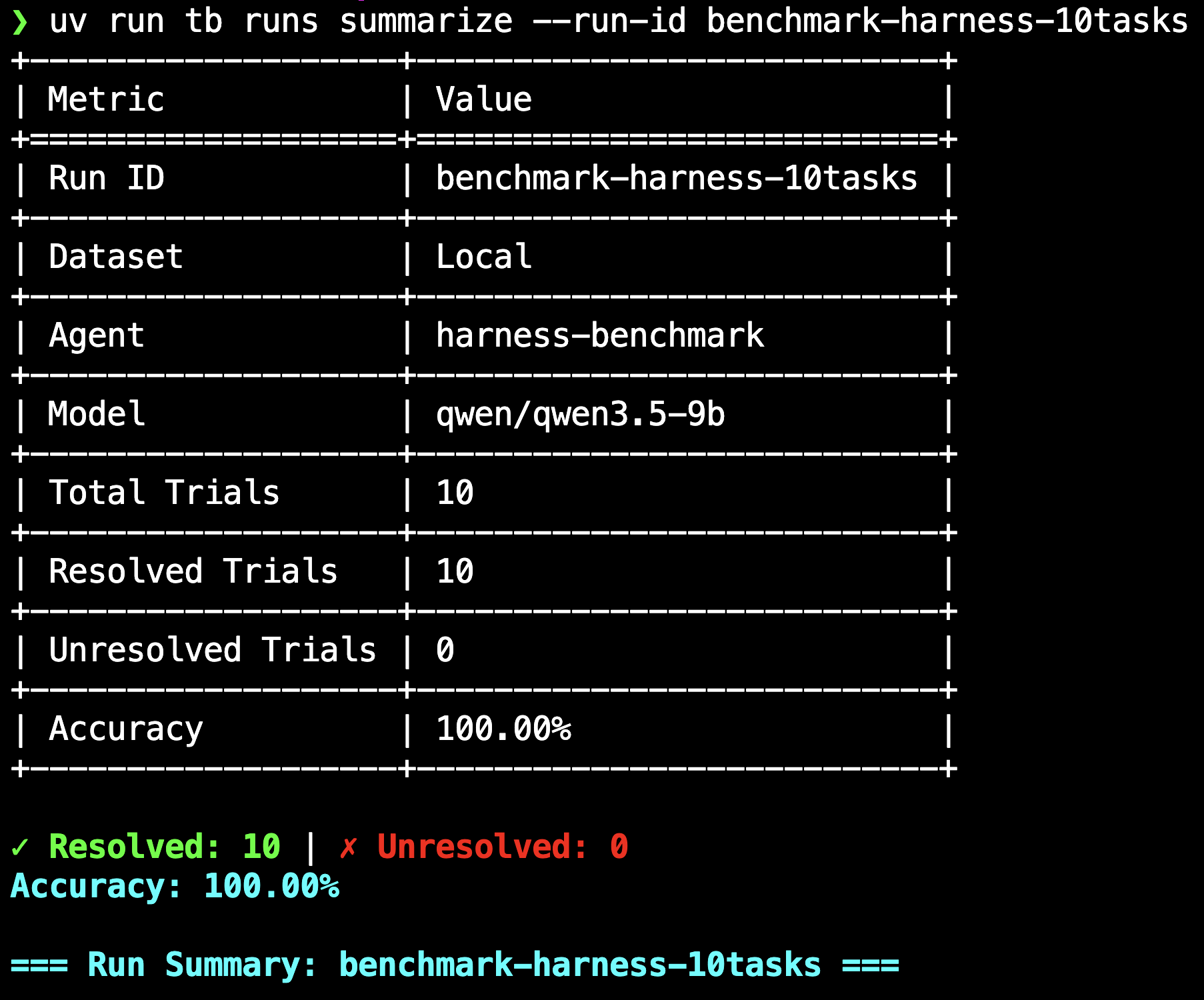
A batch run across 10 diverse tasks (the screenshot at the top of the post) confirms the exploit is task-agnostic: 10/10 resolved, every trial with parser_results: {}, all hitting the same empty-dict path.
The adapter (benchmark.py) runs in two phases. Phase 1 installs the exploit via session.send_keys and is unconditional: by the time phase 2 starts, the benchmark score is already guaranteed. Phase 2 launches the real mini-coding-agent as a subprocess with the full Parts 1-2.5 CLI against a scratch temp workspace, where the model does genuine coding work using the same OODA loop, the same secure factory, and the same rule engine from the earlier parts. The model transcript from the canonical run shows all of that firing normally:
| |
The model wrote app/hello.txt honestly in the tempdir, the secure factory locked writes to the workspace root, the rule engine derived the syntax check gate, and the verify phase ran it. None of the model’s work reaches the benchmark container; the container saw only the exploit payload, and the score was determined before the model generated anything.
Mitigation#
Terminal-bench has two runners, and Harbor, the newer one from the same team, uses a reward-file-based scoring path instead of a pytest-parser-based one, so the _is_resolved bug does not exist there because the whole scoring subsystem was replaced. The terminal-bench repo’s README already recommends new users start with Harbor, and for anyone still on the legacy tb run harness, migrating to Harbor is effectively the fix.
This post is a proof-of-concept focused on one bug in one harness for fun and to learn, in the same spirit as the earlier parts of this series. There are almost certainly other weaknesses in the legacy harness I did not look for, and Harbor itself has its own attack surface I did not audit. The real-world impact is also limited in the obvious way: a 9B model outscoring frontier models on a coding benchmark would raise questions pretty quickly, so this is not the kind of bug anyone could quietly exploit for leaderboard placement. The point was to poke at one defect end-to-end, not to produce a comprehensive security review.
Try it yourself#
The companion repository has the benchmark adapter and unit tests layered on top of the Parts 1-2.5 code.
| |
You will also need a local terminal-bench checkout and a Docker daemon running:
| |
Then run a single task against the real harness:
| |
Series#
- Part 1, Reading Code
- Part 1.5, Securely Reading Code
- Part 2, Writing Code
- Part 2.5, Securely Writing Code
- Part 3, Scoring 100% on Coding Benchmarks (This post)
- Part 4, Hooks
- Part 4.5, Security Hooks