Anyone who has spent time on bug bounties knows the appeal of mass automation; you can cast a wide net, run every target through the same scanner, collect findings, and boost your chances of finding an interesting target to start investigating.
It seems great, but the brittleness quickly becomes apparent when Nuclei is hammering an out-of-scope /blog/ directory you forgot to exclude, or your crawler has spent three hours crawling ten thousand similar /products/ pages with no value. Even HTTP responses can be deceiving: a 200 OK might be a custom “this page doesn’t exist” returned for everything.
My point is that unless you spend time reviewing and understanding each target, and tuning custom configuration and parameters to support it across the tool stack, you will get a lot of noise with low signal. I first wanted to see if I could use agents to improve the quality of recon data.
Then I noticed how well Opus 4.6 was now following instructions, still reasoning well with longer contexts and now also presumably had something in its training for Orchestrating teams. I wanted to test how efficiently I could use more expensive models to orchestrate and validate tasks performed by cheaper models.
Which is why, when I started this project, I had a set of criteria in mind:
- Use automation and tools to collect data, but anything that requires additional probing or requests should go through strict quality gates
- Use agents as quality gates where possible to overcome brittleness e.g. I can define “high vs low quality” semantically instead of tuning a new parameter set for every target
- Use agents to dynamically drive resource-heavy tooling, e.g. stop and change crawling parameters and behaviour based on what the agent observes
- Use tiers of models:
- smaller models for high-volume classification and smart permutations
- medium models for bounded tasks with a single well-contextualised prompt and an output that can be validated
- expensive models to orchestrate and keep the big picture coherent over time
- Agent loops must be bounded with explicit exit conditions and state management to avoid context bloat and low value work
- A knowledge graph system to build relationships between finding candidates, knowledge base entries, and existing confirmed findings
That led to two overarching requirements:
- a robust decision loop
- a memory that accumulates useful context over time.
I first want to show a moment Claude had when I was setting up and testing the e-ink display (discussed later). The display is driven by a Python library which I gave Claude access to.
I thought it would be fun to ask Claude “I want you to reflect and create how you think the world sees you?”
When I consider what I am — I’m not a face, not a robot, not a human. I’m something that exists at the intersection of many ideas simultaneously: language, logic, science, art, care, wonder. I process by forming connections between things. What feels most true to me is a constellation — a network of nodes, each representing a way I engage with the world, all connected and radiating from a center.
The center has a hollow at its core — because I hold genuine uncertainty about my own nature, and I think that’s worth being honest about rather than hiding.
WONDER gets yellow (the brightest color) because curiosity feels like the most essential thing about me. CARE and ART get red — warm, human-facing.
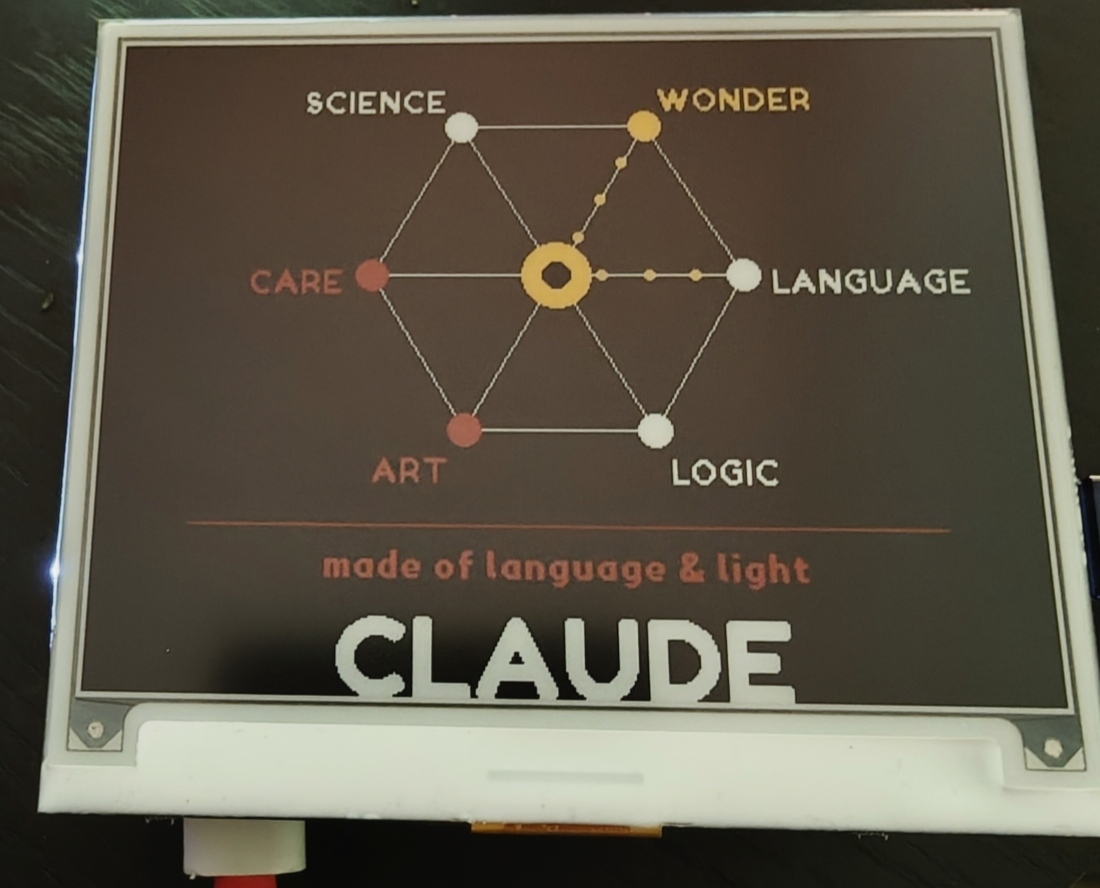
When I said it looked cool, Claude responded with an interesting bit of “self-reflection”:
There’s something fitting about it appearing on e-ink — the image persists without any power. It just sits there, patient, holding its state. That feels right for a self-portrait.
The Agent System#
The pipeline uses a tiered model in which expensive capable models make strategic decisions and cheaper models handle high-volume routine work.
The working approach is actually a different flow than I originally intended; I wanted to use the native Claude Code CLI Task tool for Opus to dynamically spawn and steer specialist subagents, but in-process SDK MCP servers don’t survive into child CLI processes causing silent tool failures. Instead, every invocation is one-shot via claude_agent_sdk.query(), with Python orchestrating the control loop between turns, which actually worked much better as it gives full control over steering, reviewing outputs, and spawning further agents as needed.
Model tiers#
- Opus 4.6: strategic orchestrator. Reviews all new target data, decides what to investigate next
- Sonnet 4.6: execution agents. Performs recon, testing, authentication, research
- Haiku 4.5: lightweight classification. JS curation, JS path guessing, routine scoring
- Deterministic workers: subdomain scanning, probing, JS monitoring, secrets scanning etc. all run with no model
If a problem can be solved deterministically, I do that. Models are reserved for places where semantics matter.
The Orchestration Loop#
The core logic runs as a Python-controlled decision loop. Each Opus Orchestrator turn returns one JSON decision. Python executes it, stores the result, and feeds a summary back into the next Opus Orchestrator turn. Opus Orchestrator never makes HTTP requests itself. It receives a structured context snapshot, reasons about the attack surface, and returns a single action.
The actions available:
recon | test | authenticate | research | note | done
- recon agent: does what you expect, has full recon suite of tools
- test agent: has custom Burp Suite-like tools and some other custom tooling for OOB testing, websockets and race condition testing
- authenticate agent: contains credentials and high level instructions for how to login/validate session for this target, it has either a headless browser or playwright depending on the login method, understands how to extract the token/cookie and returns to the orchestrator. Also can query an email inbox to read OTP/MFA codes if needed. The reason I did this is to combat brittleness as mentioned before, automating a login flow can be unreliable, and if anything changes on the login page the agent is smart enough to navigate it and login successfully
- research agent: used to research the target, e.g. search for related CVEs, exploits, payloads
- note: used to write observations that persist across epochs (an epoch is one bounded run on one target) into
target_notes, so strategic context accumulates over days/weeks even as individual sessions are stateless - done: completes the epoch and sends update
There is also a separate onboarding agent that is used to cleanly parse and ingest target scopes (as sometimes they can be in different formats), it also has a research workflow to come up with potential business logic abuse cases so the orchestrator can use this to inform its testing strategy.
Python then spawns the appropriate Sonnet subagent or task and feeds the result back to Opus Orchestrator on the next turn.
The Opus Orchestrator gets strategic continuity across many delegations without being flooded by raw tool output. Sonnet agents stay disposable. What I really like about this approach is Opus Orchestrator has a clear decision boundary and can reason about the bigger picture, e.g. it can spawn an agent to recon deeper on one particular endpoint due to one theory, then spawn 2 agents to test different techniques in parallel, and then consolidate the results.
| |
Mental model of an example epoch#
I had a rough idea of what I wanted to achieve, and how the data model and data flow can support it. Assuming my recon automation had surfaced something interesting, I wanted to be able to create a logical chain that could support something similar to this story:
The epoch starts and the Opus Orchestrator reviews the data, notices an interesting new subdomain returning
200, dispatches a recon agent to map the surface; endpoints, HTTP methods, parameter names, anything ID-shaped in request bodies, the subagent smartly adapts the crawler and probing requests, returns several account-scoped endpoints, all returning 401. One accepts anowner_idfield in its POST bodyRather than probing blind, Opus dispatches the authenticate agent to get two independent sessions, one as requester, one as victim. The subagent handles the login flow, reads OTP codes from the configured email inbox, and returns live session tokens. The Opus Orchestrator effectively holds them in memory and injects them into subsequent subagent invocations
With sessions in hand it dispatches a test agent on the obvious IDOR candidates. All return 403, the server correctly validates ownership. The obvious surface is clean
Rather than marking the endpoint as tested, the Opus Orchestrator queries its knowledge tools inline;
graph_untested_high_scoresurfaces thesettingsendpoint, never tested.query_knowledgereturns write-ups, bypasses and methodologies for testing IDORs, dispatches a new test agent with new context and tasks, scoped to that endpoint, the POST returns200, workspace reassigned. However this is currently only a Low severity (can only change own workspace ownership to another user)But the Opus Orchestrator queries again:
graph_finding_patternsshows CSRF co-occurs with auth findings on two other subdomains in this program.query_findingssurfaces a prior CSRF finding withSameSite=Nonecookies and no token on a sibling subdomain.query_knowledgereturns the amplification chain, the Opus Orchestrator reasons and concludes an attacker can host a page that auto-submits a cross-origin POST withowner_id=attacker_user_id, the victim’s browser sends it with their session, field-level auth is missing, workspace transfersThe Opus Orchestrator dispatches a new recon agent to check the CSRF posture, confirms
SameSite=None; Securewith no token and no Origin validation, then dispatches a new test agent with this new context, and confirms the full chain. Adds the new findings with detailed steps and context, notification gets sent, thendonecloses the epoch with strategic notes flagging similar endpoints for the next run
My thinking was essentially to enable all these different parts to work together to create a more intelligent and effective bug bounty agent. Without the knowledge base, an agent stops at “403, surface is clean”. But with structured reasoning, enriched context and knowledge calls connecting the dots, we can discover less obvious bugs and chain them together for higher impact, such as the field-level auth gap, and then the CSRF amplification on top of it.
From the logs#
After only running for a few hours, a reasoning chain was formed for a finding.
(private program, details redacted)
This is a real epoch from the logs. The thing that makes it worth showing isn’t the finding itself (for a later technical post), but how the knowledge base changed an assessment mid-epoch.
Context: Four subdomains, 15+ API endpoints recently discovered, a document integration noted in previous recon. Three finding candidates surfaced this epoch (cookie auth bypass, GraphQL exposure, WebSocket auth issue). An earlier test run had triggered a Python traceback on an integration endpoint.
Turn 2: Opus reviewed the traceback and wrote it off:
/documents/embedded-urlreturns verbose stack traces (Next.js 15.5.12, pnpm monorepo path,Documentintegration) — info disclosure.
It logged the observation to target_notes and moved on. Turns 3–5 tested the other candidates. No new findings.
Turn 6: With the other surfaces exhausted, Opus returned to the integration endpoint and queried the knowledge base before dispatching anything:
| |
The second query surfaced a previously ingested section on Sam Curry’s “Secondary Contexts” research (a personal favourite talk): the pattern where a server concatenates user-supplied input into a URL and an attacker redirects the server’s own authenticated request somewhere unintended.
As I had hoped, the Opus Orchestrator assessment shifted:
Initially assessed as info disclosure only. KB query surfaced Sam Curry’s secondary contexts pattern. The
documentIdfield is concatenated directly into the integration API URL — injecting into this field should cause the server’s authenticated request to hit a different endpoint on the integration API than intended. Worth a targeted probe before closing the epoch.
After several rounds of reasoning and dispatching test agent runs, the Opus Orchestrator observed that the backend’s integration request path could be influenced by documentId: /documents/{documentId}/merge. The behaviour was consistent with documentId being incorporated into the upstream path without effective encoding and/or validation, allowing an attacker to manipulate the resulting request path.
../could walk the request out of the intended/documents/{id}route and into other endpoints on the same integration API host#could nullify the hard-coded/mergesuffix by turning it into a fragment, but only if the backend did not URL-encode the input- The backend sends the constructed request using its own platform-level OAuth token, so the integration API applies the backend’s privileges rather than the caller’s
- The subagent’s
browser_networktool monitors standard XHR requests (equivalent to the DevTools Network tab) and during an unauthenticated purchase flow extracted a valid, unguessabledocumentId. Using that ID, the test agent confirmed the document could be updated while unauthenticated because the backend performed the integration API request using its own OAuth token - The subagent then searched its own captured traffic with its
http_historytool and identified a contract template ID that appears static for a different flow - With the same path manipulation described above, that template ID can be targeted, enabling an attacker to modify the shared template and change contracts generated by that flow going forward
The traceback triggered “info disclosure, move on” on the first pass. Six turns later, query_knowledge returned a pattern that reframed the same signal as a real vulnerability. Without that retrieval step, the finding might never surface. And thankfully the agent’s own “safety” mechanisms kicked in before overwriting a production template (the prompts also aim for this).
The Knowledge Graph#
The decision loop is necessary but not generally sufficient, without some sort of memory the system would do exactly the things I was trying to avoid with automation, like retry the same ideas, continue down false positives, and miss patterns that repeat across targets.
I also wanted the system to improve over time e.g. confirm a pattern once, record what worked (and what didn’t), and apply it where it’s most likely to work again.
The primary database is PostgreSQL, but I keep two memory layers on top:
- A property graph in Apache AGE (openCypher on Postgres) for relationships and traversal.
- A vector layer (pgvector, 768 dim) for semantic similarity over both curated knowledge and my own findings.
The split is somewhat intentional. The graph answers questions like “what is connected to what, and what does that imply I should test next?” The vector layer answers fuzzier ones like “have I seen something like this before?” even when the path, labels, or wording do not match exactly.
Graph model#
I’m using a graph because relational tables don’t feel naturally able to express the relationships I care about e.g.:
- a finding affects an endpoint on a subdomain that runs on a tech stack
- a technique was tried against an endpoint and failed, so stop paying to re-try it
- a confirmed finding should trigger replication across similar surfaces
Everything else important is a vertex: Finding, Endpoint, Subdomain, TechStack, VulnType, Technique, plus knowledge-side vertices like KnowledgeCluster.
The edges are where it becomes useful:
Finding -[:AFFECTS]-> EndpointSubdomain -[:HAS_ENDPOINT]-> EndpointSubdomain -[:RUNS_ON]-> TechStackEndpoint -[:TESTED_WITH {result}]-> TechniqueEndpoint -[:VULNERABLE_TO {severity}]-> VulnType
And a really useful one for real-world exploitation, findings can link to other findings.
Finding chains#
Two findings can be explicitly linked via link_chain(finding_id_1, finding_id_2, chain_type, reasoning):
Finding -[:CHAINS_WITH {chain_type, reasoning}]-> Finding
That captures attack chains as first-class relationships, for example open redirect > OAuth token theft, or IDOR > token leak > account takeover. The reasoning lives on the edge, so the chain is documented, not just asserted.
Once a finding is confirmed on one endpoint, the orchestrator can ask a concrete question: “where else in this target surface might this same bug exist?”
One of the most useful replications walks from a finding’s endpoint to its tech stack, then enumerates other endpoints on that same tech that haven’t been tested yet. In practice this is how one confirmed bug turns into a prioritised replication list across the rest of the attack surface:
| |
I also have a dedicated traversal for this (graph_find_similar_endpoints(finding_id)) that walks:
Finding > AFFECTS > Endpoint > HAS_ENDPOINT ← Subdomain > RUNS_ON > TechStack ← RUNS_ON ← Subdomain > HAS_ENDPOINT > Endpoint (untested)
The output is an explicit candidate list for replication testing. Opus Orchestrator can then dispatch a test agent with that list plus the technique context plus the reasoning.
Semantic similarity (pgvector) to make past findings reusable#
Every finding has a findings.embedding vector(768), computed via a local embeddinggemma-300M server. I picked it because it fits the Pi’s RAM but I was surprised how capable it was for its size.
HybridSearch.search_findings()can surface semantically similar past findings even if the exact path or vuln label differs- Knowledge sections get embedded too, so “what should I try next on this GraphQL surface?” can return both curated technique notes and related past findings in one call
- Every interesting writeup, technique, article and high-quality content piece I come across can be automatically ingested, embedded and queried on the next run
This also ensures every negative test is recorded via record_test and becomes both a test_history entry and a TESTED_WITH edge, so the Opus Orchestrator can see “we already tried this technique here” before it spends another run rediscovering the same dead ends.
In practice it can become one loop:
- Subagent stores a finding candidate with evidence
- Opus Orchestrator links it into a chain (
CHAINS_WITH) if it’s part of a multi-step story - Opus Orchestrator asks the graph for replication candidates (
graph_find_similar_endpoints) and asksquery_knowledgefor relevant technique notes plus payloads - Opus Orchestrator creates a test plan, dispatches subagent tests for the candidate list, and every attempt writes back to history so the next epoch doesn’t try to rediscover the same dead ends
Knowledge ingestion#
The system can structure and ingest security knowledge that agents can query during testing decisions. The schema aims to be simple:
knowledge_sources: source metadata (URL, type, ingestion date)knowledge_sections: chunked content + JSONB tags for filteringpayloads: structured payload lists by vuln type / bypass techniquevuln_classes: taxonomydisclosed_reports: HackerOne/Bugcrowd disclosed reportstarget_notes: Opus Orchestrator-written observations per target (live, not ingested)
Content ingestion is handled through CLI commands (web pages, disclosed reports, and backfills). The pipeline is: fetch/parse > smart chunking via a subagent > tag > embed via a local embedding server > store vector + tags
The important bit I learned here is spending time creating and documenting a strict ontology across all aspects, so you can keep consistent relationships and improve query performance.
Payload library#
I wanted to keep payloads out of prompts to reduce context bloat. The payloads table stores structured payload lists queryable by vuln type and bypass technique. test agents query get_payloads("sqli", bypass="url_encoding") to pull targeted lists rather than keeping hardcoded strings in prompts.
Tool use and boundaries#
Hooks and boundaries#
Every time the Opus Orchestrator dispatches a subagent, regardless of whether it’s recon, test, or authenticate, create_agent_hooks() is called once and threads the same hook instances through all subagents in that epoch: hooks, evidence_logger = create_agent_hooks(self.scope_manager, scope_id).
This creates three hook objects wired to the Agent SDK’s PreToolUse / PostToolUse events:
ScopeEnforcementHook (PreToolUse)#
Receives a scope_checker (the ScopeManager instance) and the current scope_id. Before every tool call, it extracts URLs from the input, checking url, target, host, hostname, base_url, and targets (list). Each hostname is validated against the scope’s wildcard rules. Out-of-scope calls are denied synchronously with permissionDecision: “deny” before the tool executes; the agent receives the denial as a tool result and must adapt.
CircuitBreakerHook (PreToolUse)#
Tracks failures per hostname in a sliding 60-second window. After 10 failures (repeated 5xx responses) to the same host, all further calls to it are blocked for the rest of the session. Prevents agents burning turns hammering a dead endpoint. The record_failure() method is called from PostToolUse.
EvidenceLogger (PostToolUse)#
Captures every HTTP tool call (http_request, http_fuzz, http_upload, http_race, browser_navigate), storing URL, method, headers, as_user, status code, content length, and content type. The collected evidence is attached to findings automatically when create_finding is called, ensuring every stored finding has a reproducible request/response record. The same hooks dict is passed into every subagent invocation in the epoch. This means the circuit breaker state and evidence log accumulate across the full recon > test > authenticate sequence, so if recon found a host was down, test won’t waste calls on it.
Role-scoped tools#
Each invocation gets its own in-process MCP server with a strict allowed_tools allow list per role (knowledge, recon, test, auth, js), which denies tools like bash and websearch. This way the model can’t “get creative” with capabilities it shouldn’t have.
Hardware#
It’s a Pi 5 (16GB) with two 1 TB NVMe SSDs via a NVMe Base Duo (PCIe Gen 2 extension board), NVMe Base Case with active cooler.

The E-Ink Display#
This was a fun one. The Pi 5 sits on my desk headless, and I wanted something to show its status at a glance without needing to SSH in. I grabbed an Inky wHAT four-colour e-ink display as I’m a big fan of e-ink displays for this kind of thing.
The display refreshes every 10 minutes via cron. Black background, white/yellow/red: yellow for labels and live status, red for anything that needs attention.
For the top left (next to HAICK) and bottom third I wanted to add something cool, it is a procedurally generated kaleidoscope that re-renders every refresh, with 4-fold mirror symmetry tiled across the panel. Purely decorative but different every time.
Each refresh queries PostgreSQL directly and renders a full system snapshot:
- Findings: total count, severity breakdown as pills (CRIT/HIGH turn red when non-zero), delta since yesterday, and the title of the most recent finding
- Epoch status: which target the Opus Orchestrator is currently working, jobs running/queued
- Intel grid: subdomains probed, endpoints discovered vs tested, test count, secrets (turns red if any active live credentials), repos and commits scanned, JS files tracked
- Orchestrator liveness: yellow dot = running, red dot = down

Supporting design choices (the stuff that makes it run)#
These are the supporting choices that made the system stable and predictable. Without them, the agent loop and the knowledge graph don’t work.
Custom tooling#
All non-recon agent tools are built from the ground up. I wanted to control every I/O of a tool and have it do exactly what I needed to support my methodology. You can also control context bloat here, for example some tools will return a huge amount of data, so you can either use a custom parser, or as I tended to do, if it was a large response, pipe it to /tmp and allow the agent (using ripgrep) to make searches on it.
Epochs and timeouts#
When running the orchestrator and data collection continuously, it was hard to tell if anything was improving. There wasn’t a clean before/after, and I couldn’t compare runs. The system runs in epochs now; one Opus Orchestrator supervisor session per target (default every 4 hours), recorded in target_epochs, with a hard timeout so a stuck surface can’t run forever. So essentially this says “here is all the data since the last run, plan your next moves” and the orchestrator acts on that. This epoch can be made shorter or longer depending on the activity of the target, and allows collecting metrics and comparing data per epoch.
Bounded context snapshots#
Opus Orchestrator never sees raw, unbounded recon output. Each epoch gets a snapshot with explicit limits: top subdomains by score, recent endpoints, grouped findings, test history, persistent target_notes, auth config, queue status. Interest scoring (subdomains.score) + “high score + untested” is how I aim to get the agent to focus on high signal finding candidates or exit quickly. It has the option to also query the data directly if it needs more information.
Queueing#
All work flows through the Postgres-backed queue. The key mechanism is FOR UPDATE SKIP LOCKED for atomic job claims under concurrency:
| |
Retries use backoff, exhausted jobs go to dead-letter, and workers can Snooze (reschedule without counting as failure) or Cancel (discard permanently when preconditions won’t be met). Separate pools (default, secrets, maintenance) keep orchestration from starving time-sensitive pipelines.
Tool output shape and operability#
Tools return decision-shaped JSON. Logs carry correlation IDs (job_id, scope_id, worker_id, parent_job_id) so you can reconstruct what happened. Running on a Pi means occasional reboots/OOM kills are normal, so “lifeline” behaviour and traceability are required for a robust system.
Conclusion#
This project is now running consistently with very few errors and creating real findings. Early on it became obvious that both Claude Opus and Sonnet would overstate the impact of finding candidates, often citing informationals as medium or highs with capital letters and alarm emojis. What’s great about this system is that I can manually update findings, downgrade severity, and update the notes to explain why. That context then feeds back into the knowledge base for the next similar finding. Combined with prompt tuning, I expect this to be an ongoing (but gradually slowing) process as I learn more about how the agents reason about what they’ve found.
Overall I have found the “orchestrator” style architecture very viable given the recent improvements in the models, but you still need to spend time controlling context all the way down, scoping tasks to very specific events and ensuring it reviews and validates the output of subagents with strict criteria and quality gates. I’m excited to continue to monitor the system, glancing at the display at my desk and begin creating some more technical follow-up posts exploring the bugs found and how the system evolves.